本手法の全体の処理の流れを図3.1に示す。
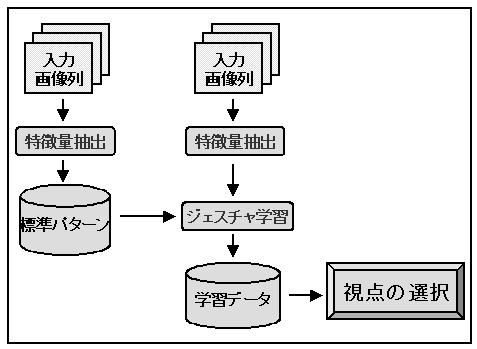
図3.1:全体の処理の流れ
まず、ある1つの動作をある1つの視点位置から撮影した画像列を計算機に 入力し、その画像列から特徴量を抽出し、それを標準パターンとして登録 する。次に、同じ動作を同じ視点位置から撮影した画像列を計算機に入力 し、その画像列から特徴量を抽出し、ジェスチャ学習部分によって先程登 録した標準パターンと比較し、その結果を登録する。その学習結果から、 その動作のその視点位置での認識しやすさを示す評価値を求める。
その処理を、認識対象となる動作全てに対して行い、その視点位置での評 価値が得られる。以上の処理を、その動作を撮影可能な他の視点位置でも 行い、それぞれの視点位置での評価値を求める。
求められた各視点位置での評価値から最も高い評価値を持つ視点位置を見 つけ出し、その視点位置を撮影した動作を認識する上での最適視点位置と する。
認識させる動作を学習する際には、入力される画像列を認識に有効な量に 変換する必要がある。この操作を特徴量抽出と呼び、本手法では16個の特 徴量を用いて認識を行う。これらの特徴量を抽出する際の、処理の流れを 図3.2に示す。

図3.2:特徴量抽出
以下に、それらの16個の特徴量の抽出方法を述べる。
入力された画像列の中の各フレームの画像に対して、あらかじめ撮影され た背景画像との差分から背景差分画像、また、1つ前のフレームの画像と の差分から時間差分画像を作成する。背景差分画像からは、フレーム中心 座標系で見た領域と、対象物中心座標系で見た領域を決定し、時間差分画 像からは、対象物中心座標系で見たものと、動作領域中心座標系で見た領 域を決定する。このように計4つの動的注視領域を決定する。各動的注視 領域から、大きさ、回転に、それぞれ依存するもの、しないものの4つの 注視条件を決定し、それぞれ特徴量を算出する。以上により、16個の特徴 量が抽出され、この操作を入力された画像列の各フレームの画像に対して 行うことにより、16個の特徴量の時系列が求められる。
これら16個の特徴量は、どのような動作を入力したときでも何らかの値を 持つものであり、本手法のように認識対象動作を限定せずに任意のものと する場合には有効な特徴量である。
ここで、各特徴量をN次元のベクトルで得られるとすると、m番目の特徴量 は以下のように表せる。
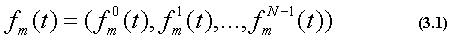
ここで、t=0,1,...,Tfであり、Tfは入力画像のフ レーム数である。また、m=0,1,...,15である。これをまとめると、最終的 に得られる特徴量は以下のようになる。
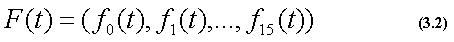
この処理では、特徴量抽出処理によって求められた16個の特徴量の時系列 を、認識対象となる動作ごとに標準パターンとして登録する。登録された 標準パターンは、それぞれの動作が特徴空間内でどのような値をとるのか を示しており、その動作を定義するこになる。この処理は、認識対象の動 作クラス全てに対して行う。
ここでの処理は、Pc(t)を動作クラスc(c=0,1,...,C)(Cは動作 クラス数-1)の標準パターンとすると、式(3.2)で得られた特徴量を用いて、
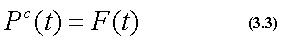
のように表すことができる。また、同様に
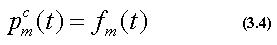
と表すことも可能である。 また、標準パターンのフレーム数を Tcp=Tfとする。
後に述べるジェスチャ学習や認識の段階では、画像列として入力された動 作と標準パターンで定義された動作との比較を行う事によって処理を進め ることになる。
ここでも、まず、標準パターン登録時と同様に、入力画像列を16個の特徴 量の時系列に変換し、F(t)を得る。
次に各動作クラスごとに、式(3.5)で示される距離 dc(t')(t)(c=0,1,...,C:t'=0,1,...,Tc p:t=0,1,...,Tf)を算出する。
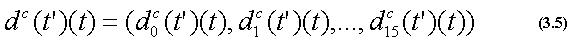
ここで、
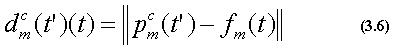
である。
また、式(3.5)で表される距離を用いて、類似度を求める。
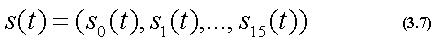
ここで、t=0,1,...,Tfであり、また、
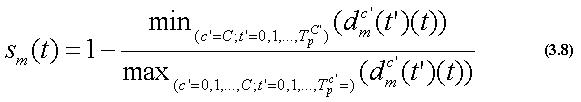
である。
以上のように求められた類似度S(t)を動作クラスcのジェスチャ学習の結 果Gc(t)として登録する。
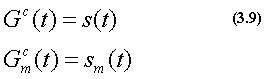
また、ジェスチャ学習のフレーム数を Tcg=Tfとする。この操作を全動作ク ラス(c=0,1,...,C)について行うことにより、ジェスチャ学習を終了する。
このように特徴量を類似度に変換する理由は、各特徴量で得られるパター ン間距離が大きさや回転などの異なる評価尺度であり、それを類似度に変 換することによってすべての特徴量を等価に扱うことが可能になるためで ある。
ここではまず、ジェスチャ学習によって得られた Gc(t)より 特徴量重みを以下の式(3.10)によって求める。
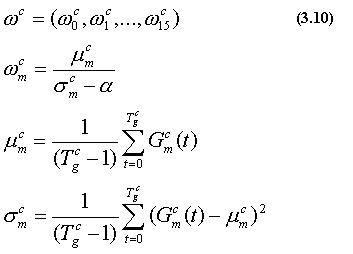
ここで、
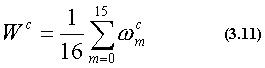
であり、また、αは特徴量協調係数であり、αが小さいほど分散σ cmがwcmに大きな影響を 与えるようになる。この特徴量重みは、各特徴量ごとの類似度の安定度を 示す。
また、得られた特徴量重みからクラス重みを式(3.12)を算出し、これを注 目すべき特徴量が定まっている度合いを示す指標とする。
このクラス重みが大きい程認識には有利であるので、全クラス重みから視 点評価値を求める(式(3.12)) 。
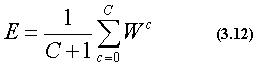
認識対象の動作を撮影した視点位置のうち、最も視点評価値が大きいもの を、それらの動作を認識するうえでの最適視点位置とする。
実際に入力画像列を動作として認識する際には、学習時と同様に入力画像 列を16個の特徴量の時系列に変換し、F(t)を算出し、それをもとに類似度 S(t)を求める。
次に、式(3.13)によって、入力画像列が動作クラスcであると仮定したと きの動作評価値ecを求める。
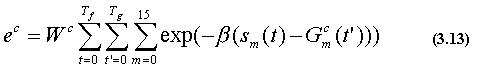
ここで、βは分離係数であり、βが大きいほど類似度要素間の相互作用が 小さくなる。以上のようにして求められた動作評価値 ec(c=0,1,...,C)のうち最大値を持つcが出力動作クラスであ り、入力画像列の認識結果となる。