従来、行なわれてきた動作認識の手法は、まず、画像を用いるものと、用 いないものに分けられる。
画像を用いる方法では、さらに二つのアプローチが存在する。一つ目は、 身体モデルを使用するもので、実画像中に含まれる人物の姿勢を推定し、 そのパラメータとして身体モデルの各関節の角度の情報を取得し特徴量と する。姿勢の推定方法としては、シリンダモデルなどの数学的幾何モデル を入力画像に適合させる方法[2]や、複数 のマーカーを人体あるいは指などに取り付けてそれらの位置関係から人物 姿勢を推定する方法[3]などが提案されて いる。これらの手法は、撮影条件、照明条件などを厳密に配慮することが 必要であり、また、モデルフィッティングの際に煩雑な計算を必要とする ため、実世界で撮影されるユーザの身振り画像を実時間で処理するには不 向きである。
もう一つは、入力画像を図形パターンとして扱うもので、2次元の画像内 での人物領域や、頭部や手などの位置を特徴量として用いるものである。 代表的手法としては、DPマッチングに基づく手法 [4]、ファジー連想記憶に基づく手法 [5]、HMM(Hidden Markov Model)に基づく 手法[6]、図形の固有空間内の軌跡の類似 性に基づく手法[7]、さらにニューラルネッ ト的アプローチに基づく手法[8]、図形モー メント特徴に基づく手法[9] [10]などがある。この方法では、身体モ デルに基づく手法と比べて撮影条件や照明条件などを厳密に配慮する必要 がなく、またモデルフィッティング処理なども不要であるために、実世界 で撮影される身振り画像を実時間で処理するには最も適切なアプローチで ある。
画像を用いない方法では、人間の体にセンサーをつけ、その出力から計算 機内で身体モデルを作成し、その情報から人間の各部位の位置や関節角を 特徴量とする。この方法では、より正確に特徴量を取得することが可能で あるが、センサーを人間につけるため、ユーザに拘束感を与えてしまい自 然な動作をすることが難しくなるためインターフェースとして使用するに は問題がある。本論文では、動作認識の将来的な使用目的として人間と計 算機との間のインターフェースを想定しているので、ユーザがより自然な 動作をすることのできるものとして、画像を使用した手法を考える。また、 将来インターフェースとして使用する際には、実時間認識を行なう必要が あるので、特徴量抽出の方法として画像を図形パターンとして扱うものを 考える。
動作認識の対象が、手話などのコミュニケーションを目的としたものの場 合、その動作は正面にいる相手に意思を伝えることが目的で決定されてい るため、認識対象の動作を特化せずに、単眼で認識する際は、対象の正面 が最適な視点となる(図2.1) 。
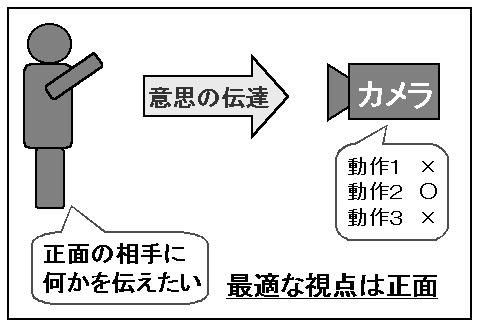
図2.1:コミュニケーションを想定した動作の認識
しかし、コミュニケーションを目的としていない動作を認識する場合や、 物体の動作を認識する場合、対象動作は、観測されることを想定せずに決 定されたものであるため、視点位置によってはその動作の特徴を捉えるこ とが困難になり、動作部位を観察することが不可能になったり、他の動作 と区別することが困難になり、認識が不可能になることがある(図2.2) 。
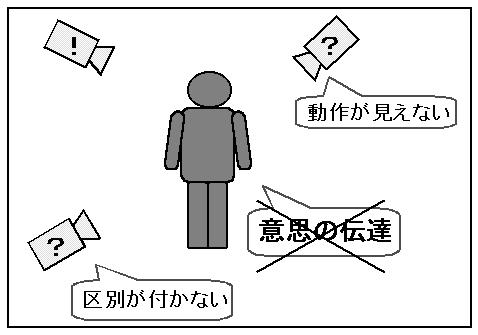
図2.2:コミュニケーションを想定していない動作の認識
したがって、動作認識をインターフェースとして使用し、認識対象の動作 を任意のものとする場合、従来手法を用いると、ビデオカメラを一点に固 定して配置しユーザを撮影することになるので、ユーザが使用できる動作 はその視点位置から認識可能な動作に限定されてしまうという問題が生じ る(図2.3) 。
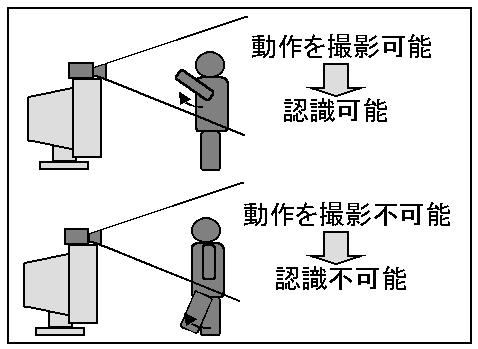
図2.3:従来手法の問題点
このことは、インターフェースの柔軟さを奪うことにつながる。そこで、 より柔軟な定義が可能なインターフェースとして動作認識を使用するには、 対象動作の特徴をより多く捉えることが必要である。つまり、インターフェー スとしての動作認識を効率良く行うためには、最適視点の選択を自律的に 行うことが必要である。
本研究では、あるオブジェクトの動作の自動認識をコンピュータによって 行う際、従来手法では、視点位置を固定していたため、そのシステムの認 識可能な動作というのは、固定された視点位置からその動作の特徴が十分 に撮影可能なものに限定されるという問題を克服するために、認識対象と なる動作を学習する際に、その動作そのものを学習するだけでなく、その 動作を撮影した位置の評価値を求めることによって、より認識率の高い視 点位置を選択する手法を提案する。この手法を使用することによって、動 作をする対象がその動作を撮影するビデオカメラの位置、つまり、視点位 置を意識することなく動作をすることが可能となる。これは動作認識を人 間と計算機のインターフェースの位置手段として応用する際には重要であ り、認識すべき動作の定義をユーザに委ねる [11]ことが可能になるため、より柔軟な インターフェースを構築することが可能になる。